As mentioned in an earlier blogpost I’m using the XML parser for a crawler. Most of the sources are well formatted and easy to read. Unfortunately not all sources are the easy to use. For one source I needed the parent element but could only select it by the attribute of a child element. I thought it would be possible to select the parent by using XPath but I needed to figure out how.
Before explaining which XPath you can use for this case, I will show some example XML for this test case:
<collection>
<users>
<user type="admin">
<id>123</id>
<name>John</name>
</user>
<user type="op">
<id>345</id>
<name>Rick</name>
</user>
<user type="op">
<id>678</id>
<name>Nicolas</name>
</user>
</users>
</collection>It’s pretty simple XML and it’s easy to select the “ops” from the XML by using this XPath:
//user[@type="op"]
This return the user element of “Rick” and “Nicolas”.
See this blogpost for using the Google Chrome console to view the result of a XPath.
But what if you want to know which type of user John is? I need to select by the name “John” but needs the user element. So we start making the XPath by selecting the user “John”:
//name[text()="John"]Now we want the parent “user” element in which the text of the element “name” is “John”:
//user[name[text()="John"]]
That’s it.
Just take one more example, but use a real test case. The website Tweakers.net sometimes posts video items. Let’s say we are only interested in those video items and want to select the table row which contains a link to a video item. We can recognize those links because they contain /video. When we combine this into a XPath it is like this:
//tr[td[@class="title"]/a[contains(@href, "/video/")]]]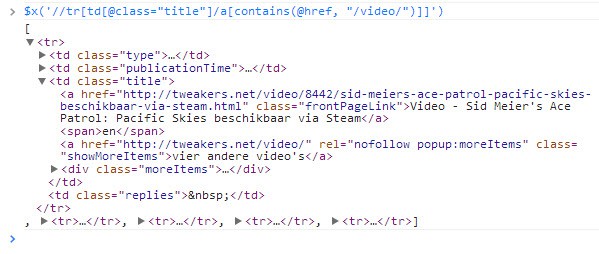
You can try this test case yourself, just head to the website and use the Google Chrome console for selecting the elements.